B Playlist
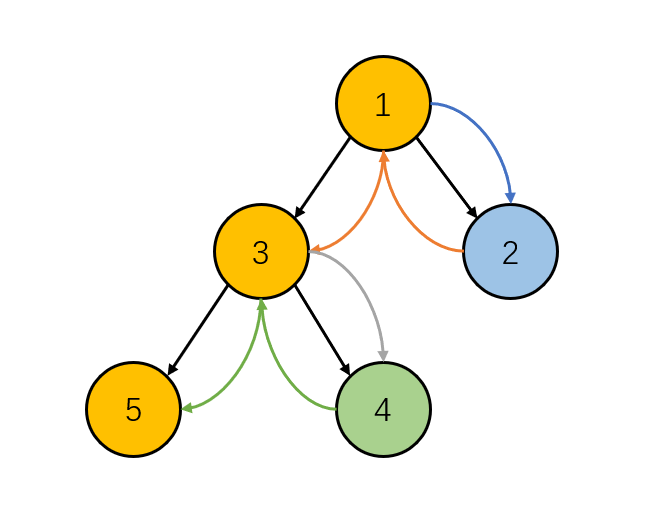
给定一个环形的数组 $a_1, a_2, \dots, a_n$,有一个指针 $p$ 在环上进行扫描,如果当前位置和上一个位置的数 $\gcd = 1$,那么删除当前位置,指针移到下一个位置重新开始,直到无法删除。
我们不能暴力模拟,因为每次可能会跳 $O(n)$ 次来找到目标删除的位置。例如:$2 \times 3, 3 \times 5, \dots, p$,每次会删除第一个数。
因此,我们需要优化这个找删除位置的过程。注意到,记 $\text{next}(i)$ 表示在剩下的位置中 $i$ 后面的那一个(环的意义下)。如果 $\gcd(a[i], a[\text{next}(i)]) > 1 $,那么这个 $i$ 位置和他后面的这一对数,在之后永远不会被当作一对删除,因此我们在找删除对的时候,不再需要考虑位置 $i$。因为,我们在不会跳过 $i$ 来删除 $i$ 后面那个,$i$ 后面那个会一直存在,直到 $i$ 被前面的删除,导致其变换前驱。
C Skyline Photo
给定一个排列 $h_1, h_2, \dots, h_n$,将这个数组划分为多个段,每个段的权值是 $h$ 的最小位置 $i$ 的权值 $b_i$,总权值是所有权值的和,求最大权值。
显然,如果权值都是正数那么只要分成长度为 $1$ 的段即可。考虑 $f(i)$ 表示以 $i$ 结尾的最大权值,那么这个权值会一直存活到下一个 $h$ 比它小的位置,这部分维护一个扫描线。然后考虑 $f(i)$ 是怎么得到的,会有两部分转移一部分是从上一个比它小的位置到这个位置的一段区间中取一个最大的,或者是从扫描线中取一个最大的。
D Useful Edges
给定一个带边权的无向图和 $q$ 组条件三元组 $(u,v,l)$。对于边 $(a,b)$,如果存在三元组 $(u,v,l)$ 和一条 $u \to v$ 的路径,满足这条路径权值和小于等于 $l$,并且 $(a,b)$ 在这条路径上,那么这条边是好边。求好边个数。
跑一下 Floyd 之后,对于一条权值为 $w$ 边 $(a,b)$,把条件列出来,存在 $1 \le i \le q$,满足 $dis(u_i,a)+w+dis(b,v_i) \le l_i$。注意到条件三元组会有 $O(n^2)$,显然不能全部枚举来判断。
移项 $w + dis(b,v_i) \le l_i - dis(u_i, a)$,这个式子的左边固定一个端点 $b$,我们枚举另外一个端点 $v_i$,然后希望预处理右边的最大值来直接判断。此时对于式子的右边就是对于固定的端点 $a$,在所有点 $1 \le u \le n$ 中,取最大的 $l(u,v) - dis(u, a)$。我们提取 $v$ 和 $a$ 作为键,$u$ 是唯一的变元,因此枚举 $u$ 预处理最大值,即可直接判断。
F Exam
给定 $n$ 个串,求有多对串 $(i,j)$ 满足 $s_i$ 是 $s_j$ 的子串,并且不存在 $k$ 使得 $s_i$ 是 $s_k$ 的子串,$s_k$ 是 $s_j$ 的子串。
首先,建出 AC 机,预处理每个点往上走第一个结束节点和 fail 树的 dfs 序。
我们枚举每一个串,计算它有多少个直接的子串。显然直接子串一定是,这个串所有前缀的最长后缀,满足这个后缀在字典中出现过,直接使用 AC 机预处理的信息容易得出(注意,完整串可能需要特判,因为完整串的最长后缀是其本身)。但是这些串中显然会有很多重复的,也会有很多串在另外的当中出现过。
我们结合 AC 机的结构,观察一下哪些串是重复的。显然每个最长后缀对应节点,在 fail 树上到根的路径都是出现过的,这些节点的串构成母串的所有子串。
但是,考虑下面这样的情况:
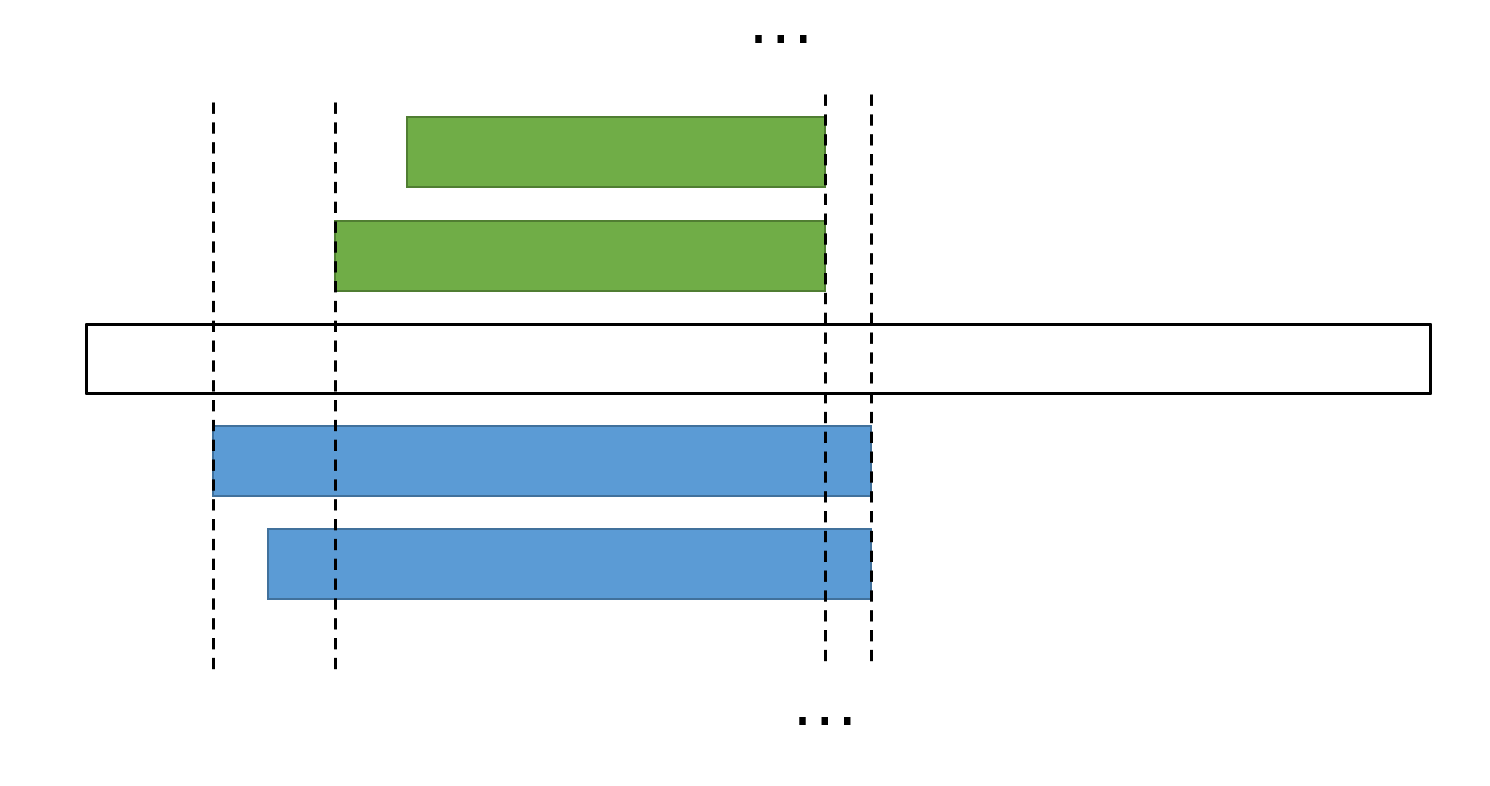
对于那个最长的绿串实际上被包含在蓝串内部,但是根据我们上述的做法,我们多统计了绿串。因为上述做法,只排除了后缀的情况,没有排除不是后缀而是内部的情况。
正确做法是,我们可以通过从右往左枚举右端点,记录单调下降的左端点,将所有左端点变化处作为询问的关键点,这样就能够排除串在内部的情况。